【公式サイト】快適で高性能なPDF
J-OCRヘルプ
はじめに
本ユーティリティは、イメージから構成されたファイル(PDF・JPEG・BMP)ファイルを、ドラッグアンドドロップで簡単にテキスト付PDFやオフィス形式(Word・Excel・PowerPoint)やテキストフォーマットに変換できるソフトウエアです。
※「Foxit J-OCR」は、イメージ系の全てのフォーマットが変換が可能ですが、
著作権の対象となっているドキュメントの変換には、著作権者の同意が必要となります。
また、ソフトウエアを運用した結果の影響については、一切の責任を負いかねます。
・Microsoft、Windows、Windows Vista、Excel、PowerPointは、米国Microsoft Corporationの米国およびその他の国における商標または登録商標です。
・Copyright (C) 2009 Foxit Corporation All rights reserved
・一般的にマニュアルに記載の会社名および製品名は、各社の商標または登録商標です。
・当ソフトウエアおよびマニュアルの無断複製を禁じます。
※「Foxit J-OCR」は、イメージ系の全てのフォーマットが変換が可能ですが、
著作権の対象となっているドキュメントの変換には、著作権者の同意が必要となります。
また、ソフトウエアを運用した結果の影響については、一切の責任を負いかねます。
・Microsoft、Windows、Windows Vista、Excel、PowerPointは、米国Microsoft Corporationの米国およびその他の国における商標または登録商標です。
・Copyright (C) 2009 Foxit Corporation All rights reserved
・一般的にマニュアルに記載の会社名および製品名は、各社の商標または登録商標です。
・当ソフトウエアおよびマニュアルの無断複製を禁じます。
■ 起動と終了
Foxit J-OCRの起動:
Windowsの[スタート]ボタンより、Foxit J-OCRを選択または、デスクトップのショートカットアイコンをダブルクリックします。

Foxit J-OCRの終了:
「Foxit J-OCR」の終了ボタンを押します。
「Foxit J-OCR」は、イメージから構成されたファイル(PDF・JPEG・BMP)を、ドラッグアンドドロップで簡単に以下のファイル形式にすることができます。
【出力ファイル形式】
Word/Excel/PowerPoint/テキスト/PDF/JPEG/BMP
【ウィンドウの説明】
「Foxit J-OCR」の終了ボタンを押します。
■ Foxit J-OCR概要
「Foxit J-OCR」は、イメージから構成されたファイル(PDF・JPEG・BMP)を、ドラッグアンドドロップで簡単に以下のファイル形式にすることができます。
【出力ファイル形式】
Word/Excel/PowerPoint/テキスト/PDF/JPEG/BMP
【ウィンドウの説明】
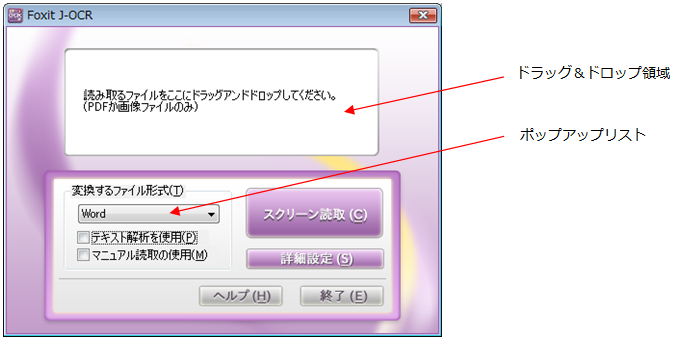
– ドラッグ&ドロップ領域:イメージから構成されたファイルをドラッグアンドドロップする領域です。
– ポップアップリスト:変換するファイル形式の選択を行います。
– ポップアップリスト:変換するファイル形式の選択を行います。
選択できるファイル形式:Word / Excel / PowerPoint / テキスト(文字認識) / テキスト(データ抽出) / PDF(透明テキスト付き) / JPEG / BMP
– テキスト解析の使用:
入力ファイルがテキストデータを含むPDFファイルの場合、テキストデータ解析後に変換します。※変換するファイル形式がWord・Excel・PowerPointのみ選択可。
– マニュアル読取の使用
変換時に「マニュアル読取」が起動します。
※テキスト解析の使用チェックボックスがオンの場合は選択不可。
– スクリーン読取
「スクリーン読取」が起動します。
– 詳細設定
「設定」ダイアログボックスが表示されます。
– 終了
「Foxit J-OCR」を終了します。
※ 制限事項
テキストデータの抽出は、PDFファイルのみが対応となります。
フォームデータには非対応です。
Unicode、Windowsで使用できない文字形式には対応していません。
テキストデータの抽出は、PDFファイルのみが対応となります。
フォームデータには非対応です。
Unicode、Windowsで使用できない文字形式には対応していません。
■ ファイルの変換
PDF・画像(JPEG・BMP)ファイルを指定したファイル形式に変換します。操作方法
1. リストから変換するファイル形式を選択します。
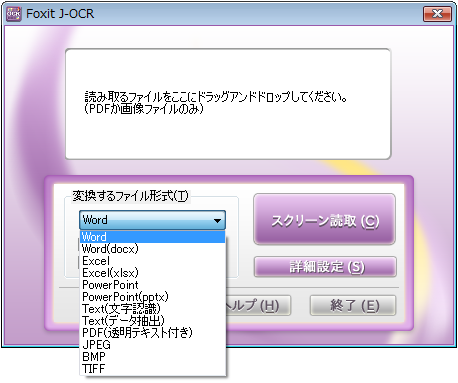
2. イメージから構成されたファイル(PDF、JPEG、BMP)をドラッグ&ドロップすると変換が実行されます。
※複数のファイルを一度にドラッグ&ドロップすることも可能です。
※複数のファイルを一度にドラッグ&ドロップすることも可能です。
2-1 Word / Excel / PowerPoint / Text(文字認識) / Text(データ抽出) / PDF(透明テキスト付き)を選択した場合:
作成されたファイルが、関連付けされたアプリケーションで開きます。
2-2 JPEG/BMPを選択し、複数ページのPDFファイルをドラッグ&ドロップした場合:
1ページにつき、1つの画像ファイルが作成されます。各ファイル名の末尾には連続した番号が付加され、別名で保存されます。
2-3 マニュアル読取の使用チェックボックスをオンにした場合:
イメージファイル(PDF・JPEG・BMP)をドラッグアンドドロップすると、「マニュアル読取」が起動します。
3. スクリーン読み取り
スクリーン読み取りを実行すると、スクリーン上の指定エリアを読み取ることができます。
“画面キャプチャーの認識”ボタンを押すと、選択ツールが表示されるので、認識したいエリアを囲い選択します。認識結果が、ボックスに表示されます。
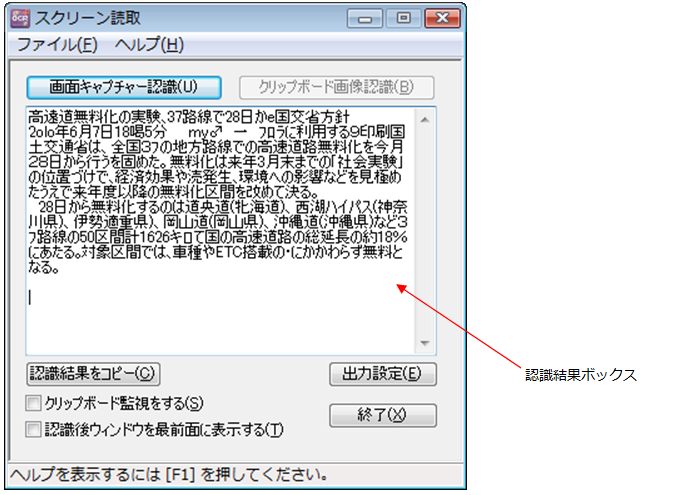
【スクリーンの認識】
スクリーンエリアを選択するツールが表示されます。
【認識結果をコピー】
認識結果がクリップボードにコピーされます。
【クリップボードを監視する】
クリップボードに新しいデータが入るとそこから認識を始めて、認識結果ボックスに表示します。
【認識後、ウィンドウを最前面に表示する】
クリップボードを監視して、認識している場合、認識後、本ウィンドウを最前面に表示します。
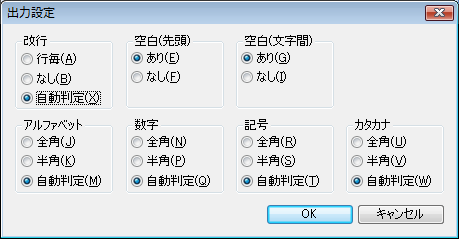
【出力設定】
認識結果の出力の設定が詳細の行えます。
詳細設定では、用途に応じて「Foxit J-OCR」の環境変更を行います。
操作方法
1.[詳細設定]より、「設定」ダイアログボックスが表示されます。
2.設定が必要なタブを選択します。
【入力タブ】 PDFおよび画像入力の設定を行います。
スクリーンエリアを選択するツールが表示されます。
【認識結果をコピー】
認識結果がクリップボードにコピーされます。
【クリップボードを監視する】
クリップボードに新しいデータが入るとそこから認識を始めて、認識結果ボックスに表示します。
【認識後、ウィンドウを最前面に表示する】
クリップボードを監視して、認識している場合、認識後、本ウィンドウを最前面に表示します。
【出力設定】
認識結果の出力の設定が詳細の行えます。
■ 詳細設定
詳細設定では、用途に応じて「Foxit J-OCR」の環境変更を行います。
操作方法
1.[詳細設定]より、「設定」ダイアログボックスが表示されます。
2.設定が必要なタブを選択します。
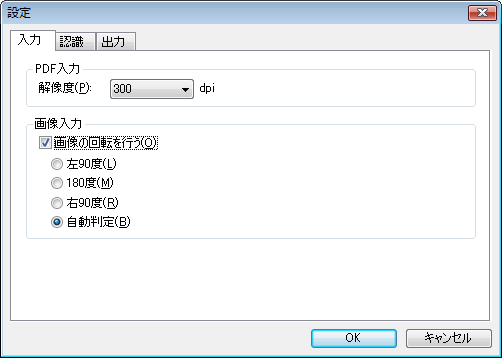
【入力タブ】 PDFおよび画像入力の設定を行います。
– PDF入力
解像度:PDFファイル入力時の解像度を設定します。[300dpi][400dpi]のいずれかを選択してください。
– 画像入力
画像の回転を行う
チェックボックスをオンにし、左90度、180度、右90度、自動判定から選択します。
※正確な文字認識をするため、PDF・画像(JPEG・BMP)ファイルの向きが正常となるように回転させてください。
チェックボックスをオンにし、左90度、180度、右90度、自動判定から選択します。
※正確な文字認識をするため、PDF・画像(JPEG・BMP)ファイルの向きが正常となるように回転させてください。
【認識タブ】 認識時の設定を変更します。
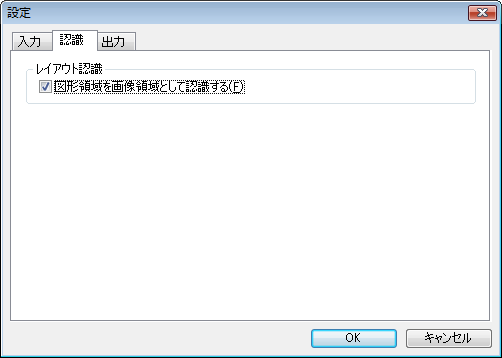
– レイアウト認識
図形領域を画像領域として認識する:
自動で図形領域と判定された場合に、画像領域とするか否かの設定
オン:図形領域を画像領域としてレイアウトとして認識
オフ:図形領域を図形領域としてレイアウトとして認識
【出力タブ】 出力時の設定を変更します。
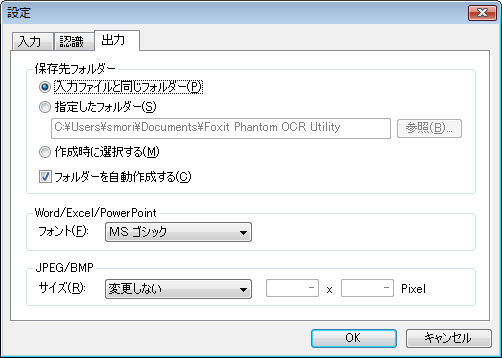
– 保存先フォルダ
– レイアウト認識
図形領域を画像領域として認識する:
自動で図形領域と判定された場合に、画像領域とするか否かの設定
オン:図形領域を画像領域としてレイアウトとして認識
オフ:図形領域を図形領域としてレイアウトとして認識
【出力タブ】 出力時の設定を変更します。
– 保存先フォルダ
入力ファイルと同じフォルダ: 入力ファイルと同じ場所に保存
指定したフォルダ: 指定したフォルダに保存
“参照”をクリックして保存先のフォルダを指定してください。
作成時に選択する: 変換時に「保存先フォルダの設定」ダイアログボックスの表示。
“保存先フォルダの設定”より、フォルダを指定してください。
フォルダを自動作成する: 入力ファイルと同名のフォルダを自動的に作成し、
そのフォルダ内に変換処理後のファイルを保存します。
指定したフォルダ: 指定したフォルダに保存
“参照”をクリックして保存先のフォルダを指定してください。
作成時に選択する: 変換時に「保存先フォルダの設定」ダイアログボックスの表示。
“保存先フォルダの設定”より、フォルダを指定してください。
フォルダを自動作成する: 入力ファイルと同名のフォルダを自動的に作成し、
そのフォルダ内に変換処理後のファイルを保存します。
– Word/Excel/PowerPoint
フォント:オフィス形式に変換される時のフォントの選択をします。
– JPEG/BMP
サイズ:画像ファイルとして出力するときの画像サイズの指定します。
※ユーザー指定の場合、高さ、幅ともに50~1920の範囲で指定可能です。
元のサイズより大きなサイズでは出力できません。
元のファイルの縦横比が維持されるため、出力された画像の幅が指定したサイズと異なる場合があります。
※ユーザー指定の場合、高さ、幅ともに50~1920の範囲で指定可能です。
元のサイズより大きなサイズでは出力できません。
元のファイルの縦横比が維持されるため、出力された画像の幅が指定したサイズと異なる場合があります。
PAGE TOP